Infrastructure and Software - May 17, 2026
Your entire digital molecular R&D lab and in-silico simulation environment deployed in minutes
Releases of Cebule™ Enterprise as a CloudFormation Template, the first full-stack computational chemistry platform available as infrastructure-as-code.
Unlike conventional chemistry software distributed as standalone packages, Cebule™ is delivered as a CloudFormation Template (CFT) that provisions an entire molecular simulation and lab integration environment:
- containerized quantum chemistry software tools (Quantum Espresso, CP2K, NWChem, LAMMPS and more)
- COSMO-RS/SAC and other solvation models
- molecular dynamics (Born-Oppenheimer, Car-Parrinello, Path Integral, and classical force field MD)
- a graph neural network library with various architectures (MCGNN, DelFTa EGNN, GANs)
- quantum computing methods and a 200-million-molecule database and a well defined schema for managing in-silico and lab data efficiently
- MLOps aligned workflow generation via Kubeflow

The Cebule pipeline: from molecular data lookup or generation through quantum chemistry and GNN methods to predicted target property values such as solubility, viscosity, and phase equilibria.
The platform supports JupyterLab, multi-agentic LLM deployment for creating your own research assistants/teams, and comes with dedicated dashboards for monitoring all calculation and workflow pipelines. The Python SDK allows for full flexibility for high-throughput screening studies with chainable TaskTypes and integrating Cebule with your own enterprise IT stack.
A research team can go from zero to running high-throughput screening pipelines with minimal infrastructure engineering required. The dedicated support by our team will allow you to request features which tailor Cebule to your needs.
The problem Molecular Quantum Solutions (MQS) solves with Cebule™
Computational chemistry has a fragmentation and multi-scale workflow problem. A typical computational R&D pipeline within pharma, life science, chemistry, or materials science touches a dozen disconnected tools: one package for DFT calculations, another for molecular dynamics, a third for machine learning, a separate database for molecular structures and calculation results, a different tool for thermodynamic property prediction, and a patchwork of scripts to glue them together. Each tool has its own dependencies, its own compute requirements, and its own learning curve. Teams spend more time on DevOps, MLOps, and compiling the necessary tools across Intel, AMD, arm and Nvidia processing units than on the science itself. Let's not even talk about integrating experimental data generation or quantum processing units (QPUs) into this mix.
Efficient workflow design and the underlying science takes a toll when battling with integration and deployment tasks.
Existing solutions address pieces of this puzzle. Some offer a Python package together with a container build procedure or a SaaS product component to unlock HPC capabilities. Others provide a managed self-hosted environment without clear integration capabilities with laboratory and experimentalist workflows. A few specialize in molecular databases.
None deliver the full stack and pipeline capabilities as a single, deployable unit.
And none let you run it on your own cloud or on-premise server infrastructure, under your own security policies, with your company-wide settings with the support of modern data management capabilities including S3 object storages.
This is the gap Cebule fills and has been tested with multiple partners where closed-loop lab integration is a major priority.
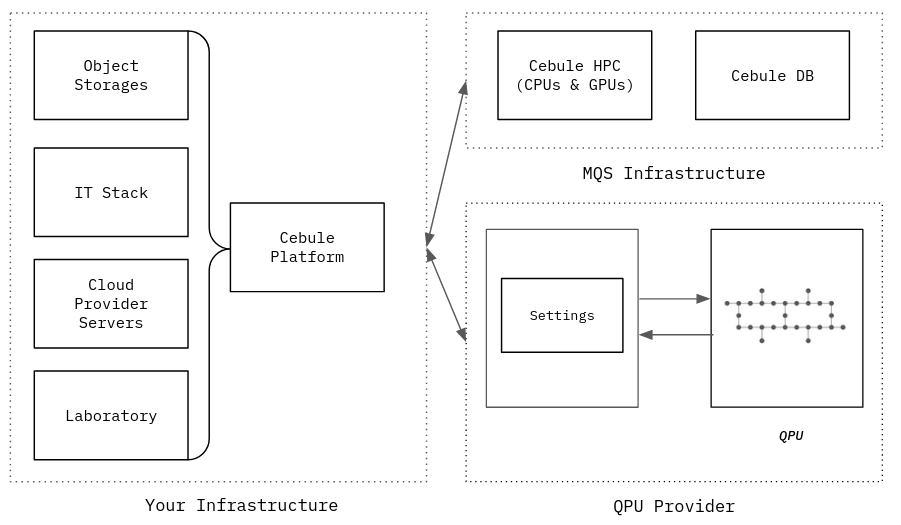
Cebule deploys into your own infrastructure — connecting object storage, IT stack, cloud servers, and laboratory equipment to MQS HPC and the Cebule database, with optional QPU provider integration.
What is a CloudFormation Template (CFT)?
A CloudFormation Template is AWS's native infrastructure-as-code format. It defines every resource your environment needs: compute instances, storage, networking, security groups, container orchestration via Kubernetes and SLURM in a single declarative file. When you launch the template, AWS builds the entire stack automatically.
For Cebule™, this means the platform is not something you install on your laptop, you rather install the Cebule™ Python SDK for accessing Cebule™'s full capacity. It is a production-grade research environment that deploys into your AWS account(s) with enterprise-level isolation, scalability, and reproducibility baked in from the start.
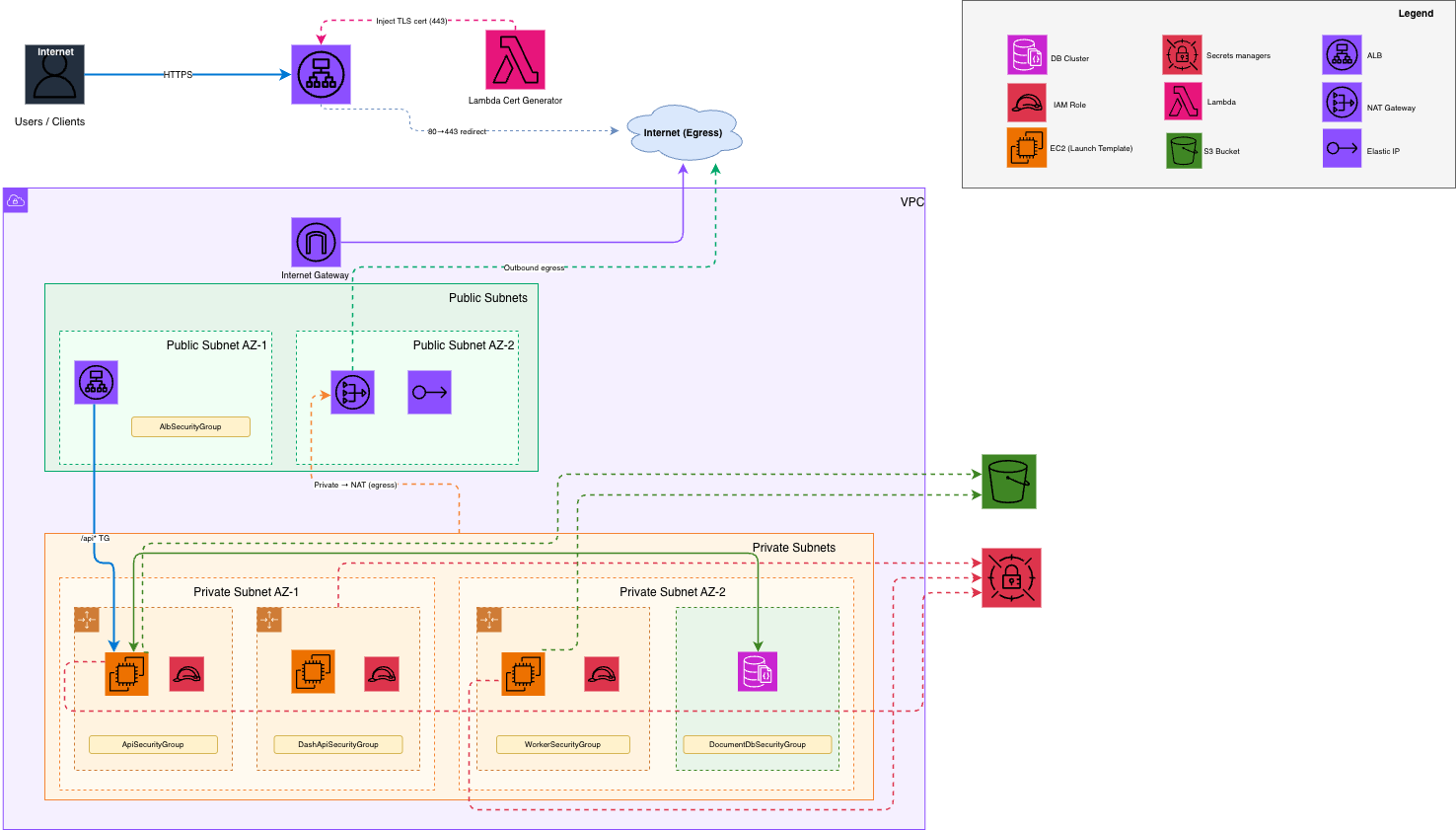
With a CloudFormation Template you can easily spin up the whole needed infrastructure via your AWS stack. Cebule Enterprise comes with dedicated support to further integrate with your needed IT/DevOps/MLOps requests.
Why does this matter?
Data sovereignty. Your molecules, your simulation results, your proprietary structures never leave your storage. You choose the region. You control the access. For pharma and enterprise customers with high-value assets operating under strict data governance requirements, this is not a feature, it is a prerequisite.
Reproducibility at scale. Every deployment is identical. When a colleague in Tokyo launches the same CFT as a team in Boston, they get the exact same environment, the exact same software versions, the exact same database state. No configuration drift. No "works on my machine" comments. Results can be easily shared and data fragmentation is prevented.
Elastic compute. Cebule™'s CFT is designed for multi-architecture compute. Pipelines can target Intel, AMD, Arm CPUs; Nvidia or AMD GPUs; and quantum processing units (e.g. IBM, IQM). You can scale up for production screening runs and scale down when no high-througput screenings have to be performed.
Infrastructure + SaaS
There is a philosophical choice embedded in how computational chemistry software gets delivered. The SaaS model where a SaaS vendor hosts your data on their servers and you access it through a browser/SDK; the SaaS model optimizes for convenience. The infrastructure model where the full stack deploys into your own environment optimizes for control, security, and long-term flexibility.
MQS chose infrastructure deliberately due to the nature of self-driven labs, experimental data and in-silico trained prediction models.
When your research platform runs in your own infra, you are not a tenant on someone else's servers. You own the compute. You own the data. You can connect Cebule to your internal databases, your proprietary computational models, your existing CI/CD pipelines, and your organization's identity management.
For enterprise procurement teams, the CFT model also simplifies purchasing. Cebule™ is available through the AWS Marketplace, which means it flows into your existing AWS contract overview, consolidated billing, and pre-approved vendor relationships. No separate procurement cycle. No new vendor onboarding.
What the Cebule™ Toolstack enables you to do
Cebule™ is a modular orchestration system that combines quantum chemistry, molecular dynamics, and machine learning into high-throughput screening pipelines. Here is what ships inside the CloudFormation Template:
Molecules Database
Access over 200 million geometry-optimized molecular structures across two curated datasets so far. The PubChemQC PM6 collection contains 221 million molecules optimized with the semi-empirical PM6 model including 80M+ neutral molecules, 35M+ spin-flipped states, and 50M+ cationic states. Each entry stores 3D coordinates, vibrational spectra with IR intensities, orbital energies, HOMO-LUMO gaps, total energy, enthalpy, dipole moments, and Mulliken partial charges across up to six electronic states.
The QMugs dataset adds 685.917 drug-like molecules from ChEMBL at two theory levels: GFN2-xTB for thermodynamic properties and DFT at ωB97X-D/def2-SVP for electronic properties with multiple conformers per molecule and downloadable wavefunction files.
Because these geometries are pre-computed, your screening pipelines become more efficient since pre-liminary geometry optimization starting with SMILES strings can become very time-consuming and consumes a lot of computational resources. The database schema is fully transparent, so you can feed your own in-silico and lab data into the database hosted on your own infrastructure while the multi TB database with open-source data is hosted by MQS for saving you storage space.
The database to SDK connection supports searching via SMILES, InChI, InChI key, ChEMBL ID, CAS number, molecular formula, molecular weight, charge, and multiplicity. With Boolean operators, wildcards, and pagination you can filter very specific molecules and structural characteristics.
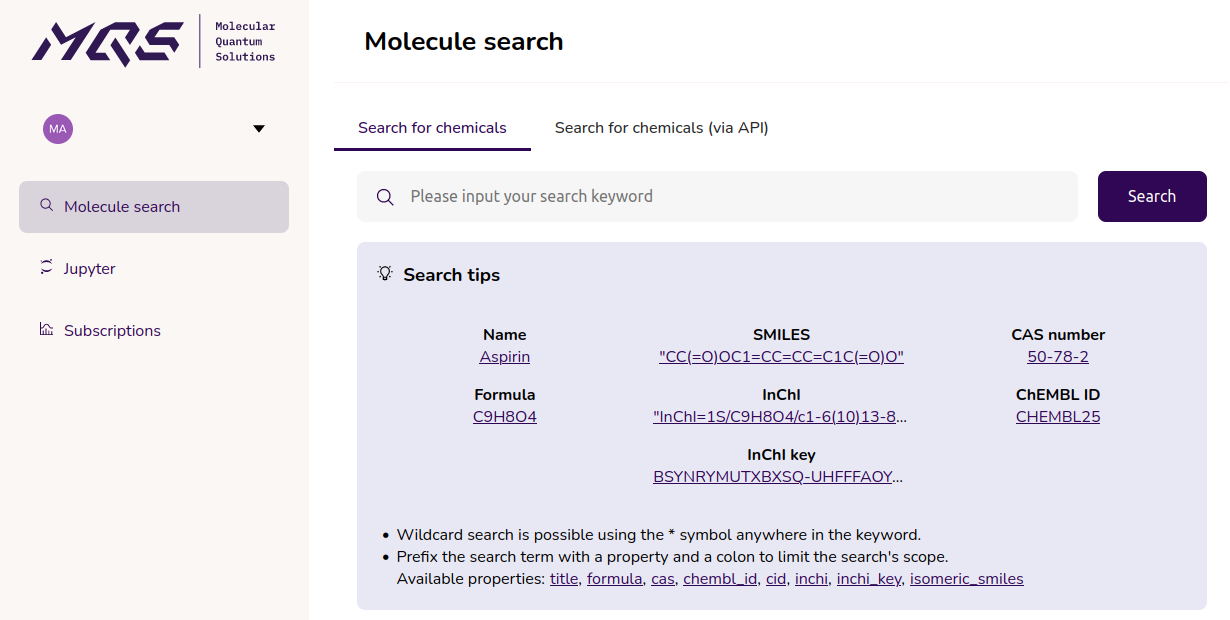
The Cebule molecule search interface — query the 200M+ molecule database by name, SMILES, molecular formula, CAS number, ChEMBL ID, InChI, or InChI key, with wildcard and property-scoped search support.
Cebule™ Python SDK
The SDK provides programmatic access to every model and database function in the platform through chainable TaskTypes:
The SDK's create_task() function provides a clean interface: you define a task type, pass your input data, and the platform handles compute allocation, running the needed containers, and result storage to S3. Tasks can be chained via connected_task_id to build multi-step pipelines: for example, GEOMETRY_OPT → COSMO → SIGMA → SOLUBILITY in a single automated sequence via the SDK or Kubeflow.
Native polymer support via pSMILES notation allows polymer-containing mixtures in geometry optimization, molecular dynamics, group contribution, and GNN tasks. The SDK integrates with other quantum chemistry and quantum computing packages. There is no platform lock-in, and workflows align with MLOps best practices. The SDK can be integrated with other workflows you have already in place.
Quantum chemistry methods
Cebule supports a layered stack of electronic structure methods spanning several levels of theories: semi-empirical and semi-empirical tight-binding models (GFN1-xTB, GFN2-xTB, PM6, PM7), density functional theory (DFT, PW-DFT) with multiple exchange-correlation functionals (BP86, ωB97X-D) and basis sets (def2-TZVP, def2-TZVPD, def2-SVP, 6-31g**) or pseudo-potentials. Machine-learned interatomic potentials (MLIPs) are available (MACE, ORB, PET-MAD, GRACE-2L, UMA) and continuously new MLIPs are added due to the fast pace of the R&D of these models.
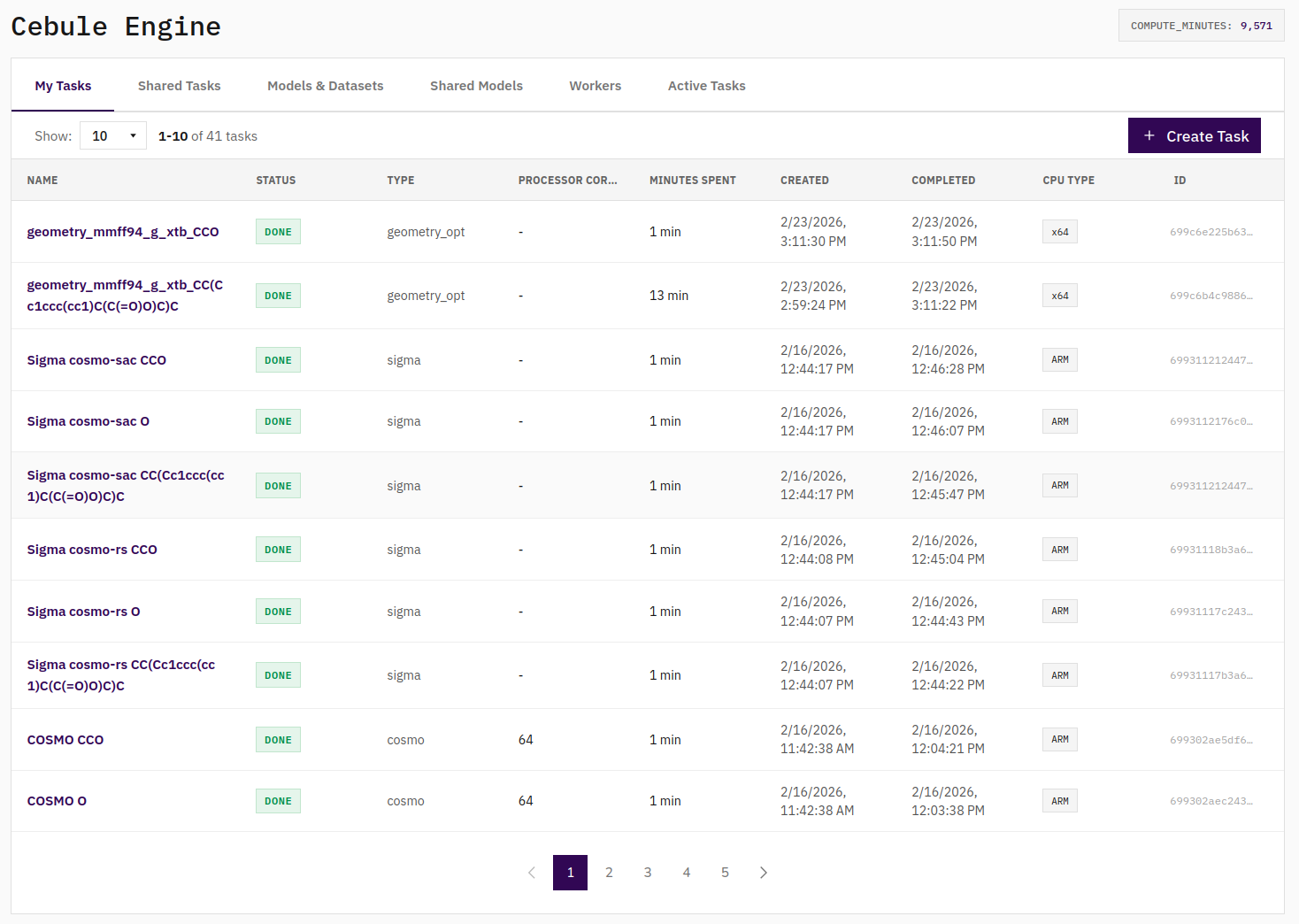
The Cebule Dashboard allows you to track all your calculations and check input and output data. Share your results with colleagues for efficiently progressing with your high-throughput studies.
Solvation and thermodynamic models
The solvation and thermodynamic models cover quantum-level surface charge generation to macroscopic mixture target property predictions:
Implicit solvation: COSMO as the production model and workhorse engine model in industry for thermodymanic property prediction.
COSMO-RS/SAC family: COSMO-RS, COSMO-SAC (2002/2007/2010 variants), COSMO-RS with intermolecular dispersion, COSMO-SAC-dsp, electrolyte extensions (eCOSMO-RS, eCOSMO-SAC), and COSMO-SAC-PDH-IL for ionic liquids.
NRTL family: NRTL, eNRTL for electrolytes, and COSMO-NRTL which can also be fine-tuned via COMSO-RS/-SAC and the binary interaction parameters allow easy exporting to process simulation tools including Aspen Plus, HYSYS, AVEVA PRO/II, and DWSIM.
UNIFAC family: Original UNIFAC, Modified UNIFAC (Dortmund), UNIFAC Surfactant for detergent and cosmetics applications, and UNIFAC-VISCO-IL for ionic liquid viscosity prediction.
Molecular dynamics
Both ab-initio and classical molecular dynamics ship inside Cebule™:
Ab-initio MD Born-Oppenheimer MD , Car-Parrinello MD (wavefunction propagated via Lagrangian scheme), and Path Integral MD for capturing quantum nuclear effects including zero-point motion and tunneling.
Classical force field MD via OpenMM with the OpenFF SAGE v2.2.1 force field or LAMMPS and native polymer/biomolecules/macromolecule chain simulation via pSMILES notation.
Machine learning and GNN models
Three graph neural network architectures for molecular property prediction:
MCGNN: A directed message-passing neural network (D-MPNN) combined with a matrix completion method (MCM).
DelFTa EGNN: Equivariant graph neural network.
GAN-based generative models for molecular structure generation.
Molecules can be mapped as a graph and message passing refers to sharing information between nodes which can be utilized via Graph Neural Networks (GNN) to train highly performant property prediction models.
Quantum computing readiness
-
Support of three main quantum computing method families: Variational Quantum Algorithms (VQA), Quantum Subspace Expansion (QSE) and Quantum Phase Estimation (QPE)
-
Additional methods and tools such as fermion-qubit mapping and measurement methods (Qubit reduction); tensor networks based quantum circuit generation (iteration and run-time optimization); zero-noise extrapolation (ZNE) for error mitigation; a genetic and zx-calculus quantum circuit generator/optimizer; an open-source benchmarking framework for VQA and QSE on IBM QPUs and other hardware providers.
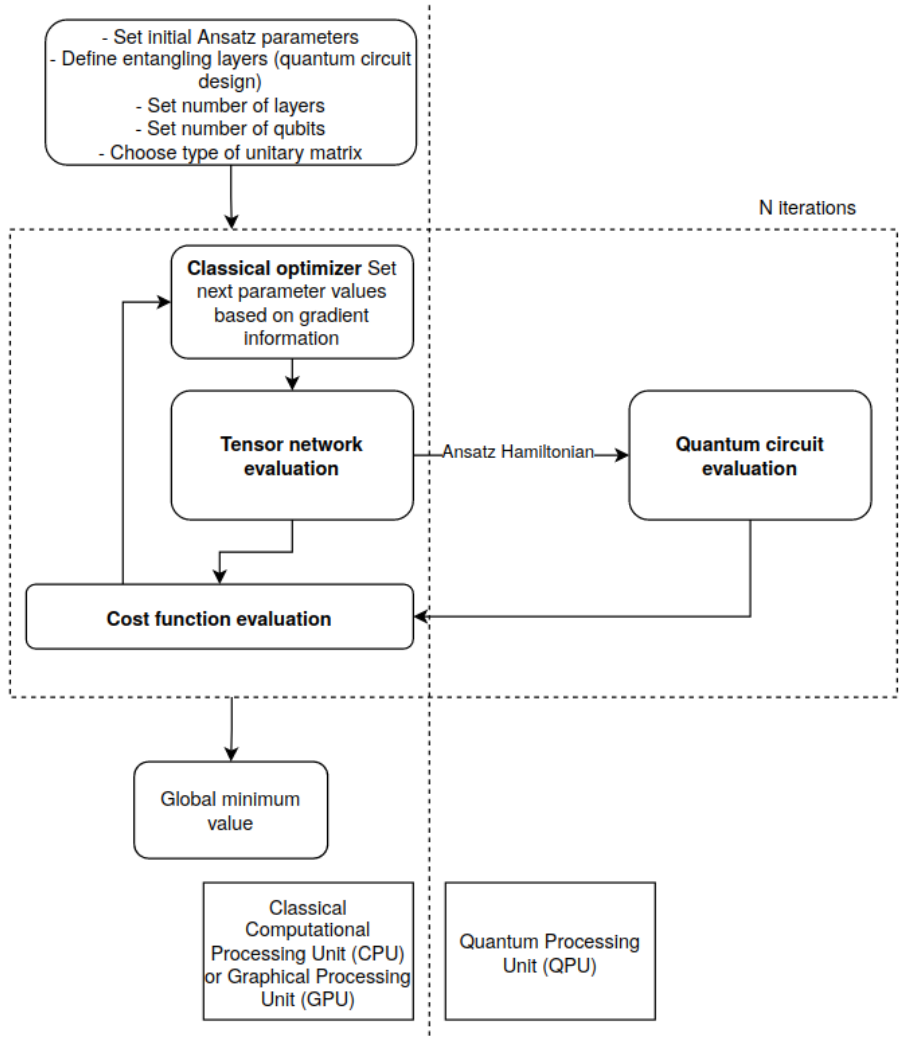
Flow diagram of the TN-VQE method developed by MQS and accessible via the Cebule SDK: a classical optimizer iterates between tensor network evaluation on a hybrid CPU-GPU-QPU setup which allows to decrease the needed number of iterations. Decreased number of iterations reduces the financial costs of running QPU based algorithms.
Mutli-agentic R&D
An agentic framework connected to the Cebule SDK documentation, the molecules database, and open-access research literature, provides direct links to molecular data and formatted CSV and Python examples. Generate complete, runnable code scripts customized to your use case with step-by-step SDK integration guides; and answers technical questions about calculation methods, parameters, and best practices. Future capabilities will allow you to deploy a selection of open-source LLMs to design your own multi-agentic research teams.
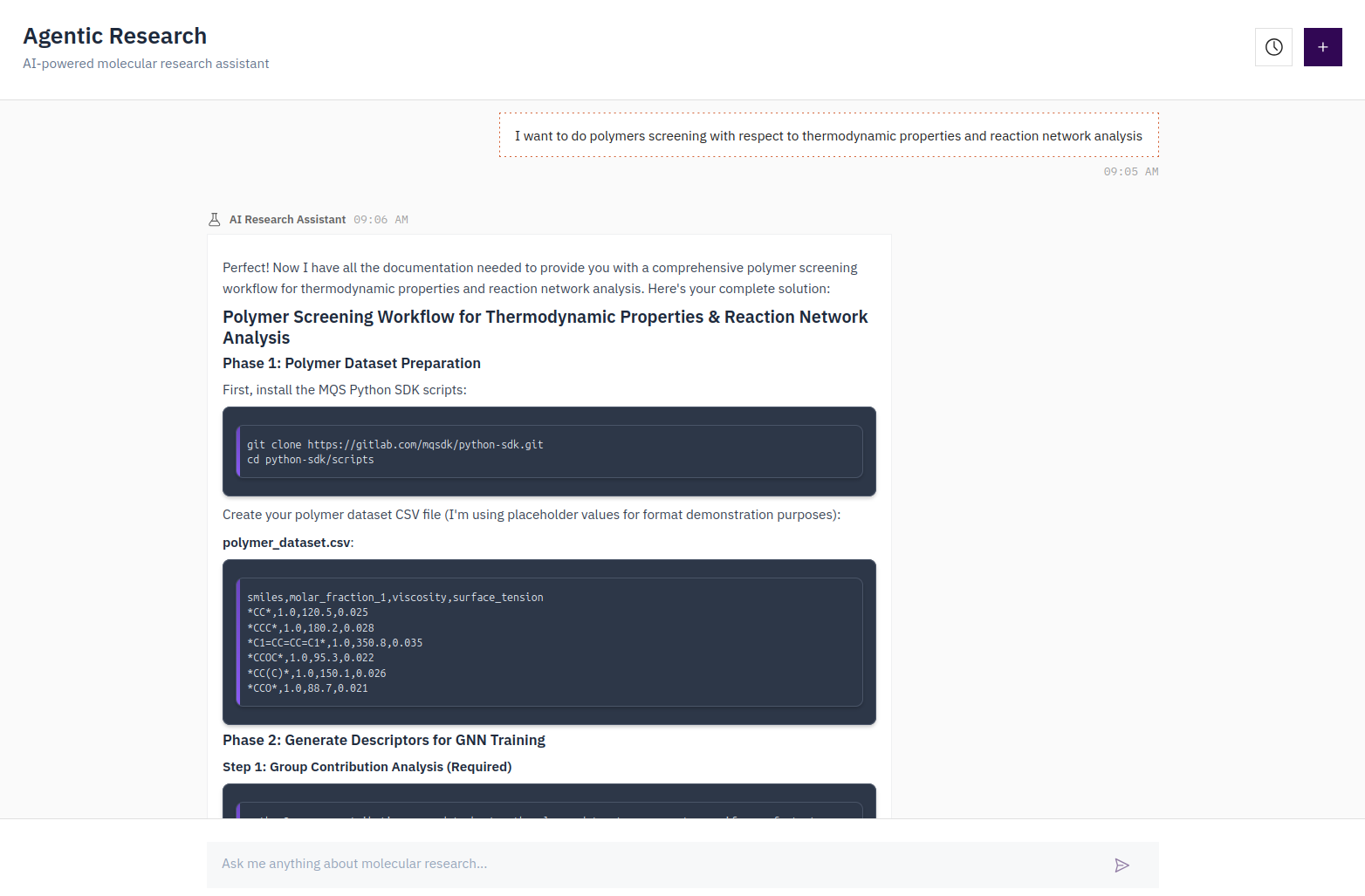
The Cebule Research Agent responding to a polymer screening query — it generates a complete, runnable multi-step workflow including dataset preparation, descriptor generation, and GNN training steps.
Cebule™ Dashboard
A collaborative workspace where research teams store queries, code examples, and custom workflows in one place. The dashboard provides molecular search, interactive property visualization, dataset comparison, HPC tasks monitoring, wavefunction file downloads and a prompt overview of all your AI agent research topics. It includes a hosted JupyterLab and Kubeflow environment with adjustable compute power. Researchers can develop and refine pipelines without switching between tools and multiple logins.
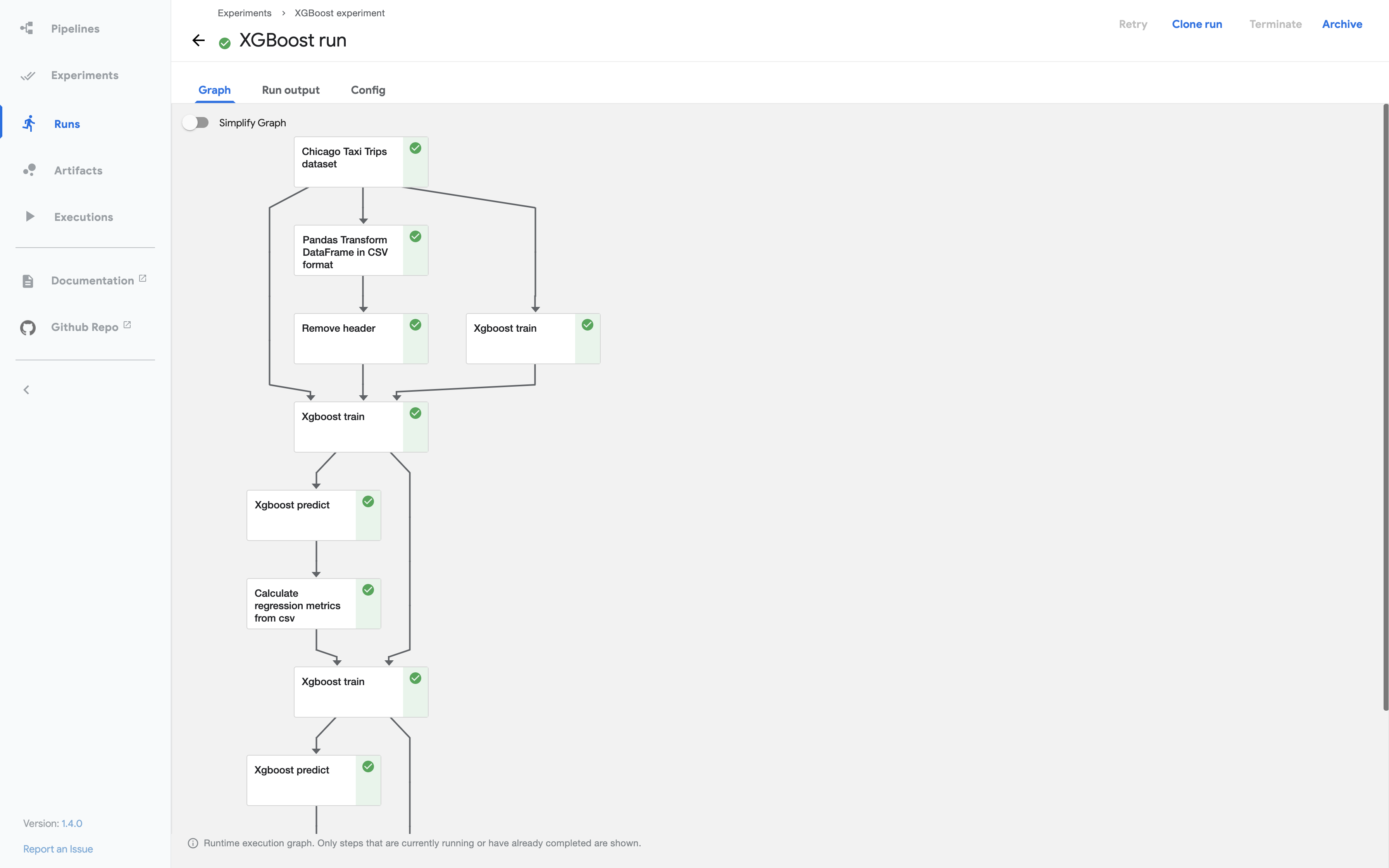
Kubeflow is integrated with the Cebule Dashboard and you can access the database&models to build highly modular, reproducible ML workflows with shared or private pipelines, experiments and artifact tracking.
Object Storage Connectors
Each team member or group can connect their own S3 buckets to the Cebule platform. All task results are stored to S3 automatically. This allows you to efficiently handle all generated data and align with your company's internal data management practices.
Quantum Computing Connectors
Apart from the quantum computing methods integrated in Cebule, the choice of quantum compute hardware (QPU) is up to you. Cebule™'s connector capabilities allow you to select your QPU provider with your own credentials — IBM Quantum, IQM, Xanadu or other QPU providers. The platform is quantum-compute-ready and already allows you to integrate or combine quantum computing methods together with classical pipeline calculations on CPUs and GPUs.
Lab Connect
Cebule includes a comprehensive laboratory digitalization framework. The infrastructure supports OPC-UA gateways for heterogeneous equipment, MQTT real-time messaging, a PostgreSQL time-series database schema, and ROS2-based robotic automation tested with with UR5e and Meca500 robot arms. Advanced capabilities include Bayesian closed-loop optimization connecting in-silico predictions with experimental validation, digital twins with incremental learning and soft sensors.
Getting started
Currently the Cebule™ Enterprise deployment requires an AWS account.
- Subscribe to Cebule™ on AWS Marketplace: Link
- Launch the CloudFormation Template, selecting your preferred AWS region and instance types.
- Access the Cebule Dashboard and JupyterLab environment through the URLs provided in the stack outputs and start working with the Cebule SDK for high-throughput screening studies.
- Explore the Molecules Database and start building pipelines using the Research Agent's guided setup, while Kubeflow allows you to build and monitor these pipelines through a visual dashboard or the Kubeflow SDK.
Resources
CloudFormation Template: CFT Link
Documentation: docs.mqs.dk
Video Tutorials: youtube.com/@Molecular-Quantum-Solutions
Research Agent: cebule.ai · cebule.io · cebule.eu
About Molecular Quantum Solutions
Molecular Quantum Solutions (MQS) is a Copenhagen-based deep-tech company providing a infrastructure+software setup for computational chemistry , quantum computing and chemical engineering applications. Founded in 2019 and headquartered at Quantum Denmark (Niels Bohr Institute), MQS has developed the Cebule™ platform over six years and offering services to pharmaceutical, biotech, chemicals, materials science, food, cosmetics, and biomaterials companies. MQS collaborates with research and industry partners including DLR, Fraunhofer SCAI, BioInnovation Institute, planqc, Oxford Ionics, d-fine and many others.
Contact: [email protected]
Back to all articles